
Exploading load on prod
Today, I had an interesting problem to solve. Since a few weeks, I’d sporadically get bugged by the on-call team about a production server with a legacy app that generate excessively high load. The on-call guys usually check the obvious things like disk capacity, memory etc, but it’s always good to double-chek.
But again - Disk - IO is fine, capacity is fine (and the app mainly just reads
and writes to DB). Network IO (or waiting for DB responses) wouldn’t generate
load on the app server, so my usual approach would be to break out strace and
see what the load-generating processes actually do. But alas, the processes
don’t interact with their surrounding at all!
# strace -ffp 11697
… And nothing shows up.
So it’s really computing something… but what? I know the load normalizes when restarting the processes, so I’m being very careful not to do this, lest the ability to analyze the issue vanishes for another couple of weeks.
Thinking about it, I really can’t figure out what exactly could be the source of this problem. I know for certain that no hard computation is done that could even take more than a couple of milliseconds. The most computationally intensive bit is rendering a small picture: Basically, writing a barcode and some text onto a small-ish PNG. That hardly can’t be the problem, as it always worked during development, and also for years on prod. So what could be the problem?
Let’s start digging
I finally decided to dig out the heavy tools. I’m installing GDB on the machine, and get to work attaching to one of the load-generating processes:
# gdb -p 11697
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-114.el7
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Attaching to process 11697
(some output regarding symbol loading omitted)
Once in GDB, I first check out the stack - maybe it’s telling us something?
(gdb) bt
#0 0x00007f4eaa5fb6b3 in sre_ucount () from /lib64/libpython2.7.so.1.0
#1 0x00007f4eaa5f9c93 in sre_umatch () from /lib64/libpython2.7.so.1.0
#2 0x00007f4eaa5fb29e in sre_usearch () from /lib64/libpython2.7.so.1.0
#3 0x00007f4eaa5fc968 in pattern_search () from /lib64/libpython2.7.so.1.0
#4 0x00007f4eaa5bbcf0 in PyEval_EvalFrameEx () from /lib64/libpython2.7.so.1.0
#5 0x00007f4eaa5be03d in PyEval_EvalCodeEx () from /lib64/libpython2.7.so.1.0
#6 0x00007f4eaa5bb53c in PyEval_EvalFrameEx () from /lib64/libpython2.7.so.1.0
#7 0x00007f4eaa5be03d in PyEval_EvalCodeEx () from /lib64/libpython2.7.so.1.0
#8 0x00007f4eaa5bb53c in PyEval_EvalFrameEx () from /lib64/libpython2.7.so.1.0
Hmm. Looks like regular python at work, currently matching some regex. Nothing
unusual there! Let the process continue, hit Ctrl+c and check the stack
again. Huh, Regex again? I repeat the process for a couple of times, and it
seems to always be in sre_umatch() or close to it. Curious!
Regexes? This slow?
I know that complicated regexes can be problematic regarding performance, but this app worked perfectly fine for the last three or four years, so what’s going on?
Trying to dig deeper, I figured I couldn’t find out much without looking into the actual regex being processed here. But for this, I first need the debug symbols installed. Luckily, on CentOS this isn’t too hard. I exit GDB and install the python debug packages:
# debuginfo-install -y python python-libsNow, attaching to GDB again, let’s see what we have now:
# gdb -p 11697
(you don't wanna see all that startup output)
(gdb) bt 5
#0 0x00007f4eaa5fa375 in sre_umatch (
state=state@entry=0x7fff36eb42d0,
pattern=pattern@entry=0x7f4ea04a0094) at /usr/src/debug/Python-2.7.5/Modules/_sre.c:1258
#1 0x00007f4eaa5fb29e in sre_usearch (
state=state@entry=0x7fff36eb42d0,
pattern=0x7f4ea04a0094, pattern@entry=0x7f4ea04a0080)
at /usr/src/debug/Python-2.7.5/Modules/_sre.c:1614
#2 0x00007f4eaa5fc968 in pattern_search (
self=0x7f4ea04a0030,
args=<optimized out>,
kw=<optimized out>)
at /usr/src/debug/Python-2.7.5/Modules/_sre.c:1933
#3 0x00007f4eaa5bbcf0 in call_function (
oparg=<optimized out>,
pp_stack=0x7fff36eb4a90)
at /usr/src/debug/Python-2.7.5/Python/ceval.c:4408
#4 PyEval_EvalFrameEx (
f=f@entry=Frame 0x7f4ea04fa620, for file
/srv/app/VENV/lib/python2.7/site-packages/django/core/urlresolvers.py,
line 227, in resolve (
self=<RegexURLPattern(
_regex_dict={u'de': <_sre.SRE_Pattern at remote 0x7f4ea04a0030>},
default_args={},
_callback=<function at remote 0x7f4ea0704488>,
name='print_order',
_regex='^print/((?:[0-9]+,?)+)/$')
at remote 0x7f4ea0727c90>,
path=u'print/631385,631384,631383,631382,631381,631380,631379,631378,631377,631376,631375,631374,631373,631372,631371,631370,631369,631368,631367,631366,631365,631364,631363,631362,631361'),
throwflag=throwflag@entry=0)
at /usr/src/debug/Python-2.7.5/Python/ceval.c:3040
#5 0x00007f4eaa5be03d in PyEval_EvalCodeEx (
co=<optimized out>, globals=<optimized out>,
locals=locals@entry=0x0, args=<optimized out>,
argcount=2, kws=0x55b2176cd520,
kwcount=0, defs=0x0, defcount=0, closure=closure@entry=0x0)
at /usr/src/debug/Python-2.7.5/Python/ceval.c:3640
(Note: I’ve normalized the output a bit for better readability)
Oh look! We’ve ended up in a regex parsing function yet again! But this time, we see some very very useful information: The regex, along with a URL? Are you telling me that this puny little regex here takes this long to process?? Can’t be, can it?
Anyway, doesn’t hurt to look at it in more detail:
The Regex looks innocent enough: ^print/((?:[0-9]+,?)+)/$ This is part of the
urls.py of our app, matching a print view that can get a bunch of “orders” to
display. It’s meant to accept a comma-separated list of numeric identifiers.
So, still not believing that this is actually the problem, I pasted the regex
into regex101.com, along with the URL path which was
conveniently also found in the call stack:
print/631385,631384,631383,631382,631381,631380,631379,631378,631377,631376,631375,631374,631373,631372,631371,631370,631369,631368,631367,631366,631365,631364,631363,631362,631361
The URL itself is nothing unusual either, that’s a normal path to show a bunch of orders.
Looking at Regex101, I first noticed that the pattern didn’t match. Suspicious. But then I saw the error message: “Catastrophic backtracking!”
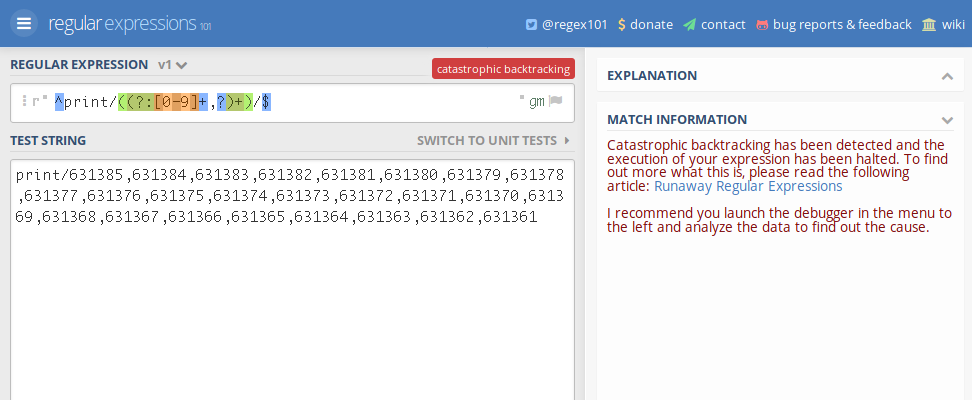
This is the moment where I actually read the regex, instead of just skipping over it and assuming it’s doing it’s intended purpose as implied by the context.
Ooookay! So the regex is the problem! And worse, you can trigger it before it gets to the view function, which does authentication. So someone with a bit of criminal energy could actually DoS this server rather easily. But that’s not my problem. My problem is that regular users are DoSing the machine!
Before going on to fix it, let’s try and see how bad it really is:
~ % python2
Python 2.7.15 (default, Jun 27 2018, 13:05:28)
[GCC 8.1.1 20180531] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> import timeit
>>> url = 'print/631385,631384,631383,631382,631381,631380,631379,631378,631377,631376,631375,631374,631373,631372,631371,631370,631369,631368,631367,631366,631365,631364,631363,631362,631361'
>>> expr = r'^print/((?:[0-9]+,?)+)/$'
>>> timeit.timeit(lambda: re.match(expr, url), number=10)… and it hangs. After a few minutes, I cancel it. Shorten the URL. Try again. Shorten URL again. Try the match AGAIN. Getting angry. Finally I have a URL that works:
>>> url = 'print/631385,631384,631383,123433'
>>> timeit.timeit(lambda: re.match(expr, url), number=10)
1.0487539768218994So short, and still that slow! Ten iterations, and it still takes about a second? That regex is really really bad. As in: How did we not catch this during development?
Of course when writing that feature, we only ever tested with a small handful of entries at most. And on the test systems, the identifiers were much lower, making the URL shorther as well. Half a second to parse a URL doesn’t raise suspicion when testing manually, I suppose.
Down the rabbit hole
At this point, I know how to fix the problem, but I’m intrigued. Why exactly is this so bad?
Maybe you’ve noticed, but the URL above will not even match: The regex requires a trailing slash, but the URL doesn’t have one! What happens to the above test script if we add a slash to the URL?
>>> url = 'print/631385,631384,631383,123433/' # Same as above, with slash
>>> timeit.timeit(lambda: re.match(expr, url), number=10)
0.00010395050048828125Wow. Ten. Thousand. Times. Faster. Let that sink in.
The problem, explained
I don’t know enough about regex engines to know what exactly happens inside, but I assume that if we get a match, the engine immediately stops without trying further. Thus, it tries one variant, matching a bunch of characters just as they show up, eating up the string until the end, done, everybody’s happy.
If it doesn’t find a match, however, it has to try every single variant there
is to match the string. And as it turns out, there are quite a few!
Let’s look at it again and split out the bits a little bit. Here’s the
original regex again: ^print/((?:[0-9]+,?)+)/$
- The prefix match is trivial:
^print/ - Then comes a non-capturing group - nothing bad either. The content of the
group:
[0-9]+,?- Match any number of digits, optionally followed by a comma. - Then the rest - Repeating above group one or more times, followed by a trailing slash.
Thinking about this a bit more, it’s dawning on me just how horribly, horribly bad this is: The regex tries to match a bunch of digits, followed by a comma. But wait, the comma is optional! This means that at every digit, the algorithm has the choice of eating one more digit in the character list, or moving on to the next group. And there, the same choices come up for each digit again. So every digit in the URL means the number of paths doubles!
The solution
I think the original intent for the regex was to kind-of sanitize the list of numbers. We don’t want any non-number bits in the list, and the list should also be well-formed: No trailing comma, for example. But reading that regex - it fails at that also!
So in the end, I just simplified the regex to what should have been done from the beginning: Just match any number or comma, in any order. The final change in the source looked simple enough:
- url(r'^print/((?:[0-9]+,?)+)/$', app.print_order_view, name='print_order'),
+ url(r'^print/([0-9,]+)/$', app.print_order_view, name='print_order'),
The view function can handle empty bits in the list anyway, so why bother doing too much here?
I’m quite confident this thing won’t overload the server anymore now.